This blog is a continuation of the database systems series, covering Lectures 3 and 4 of the Database Systems CMU 15-445/645 course.
How does a DBMS store data?
A DBMS uses disks for data storage and persistence, and there are many storage devices that the database can use to store data.
Storage Devices
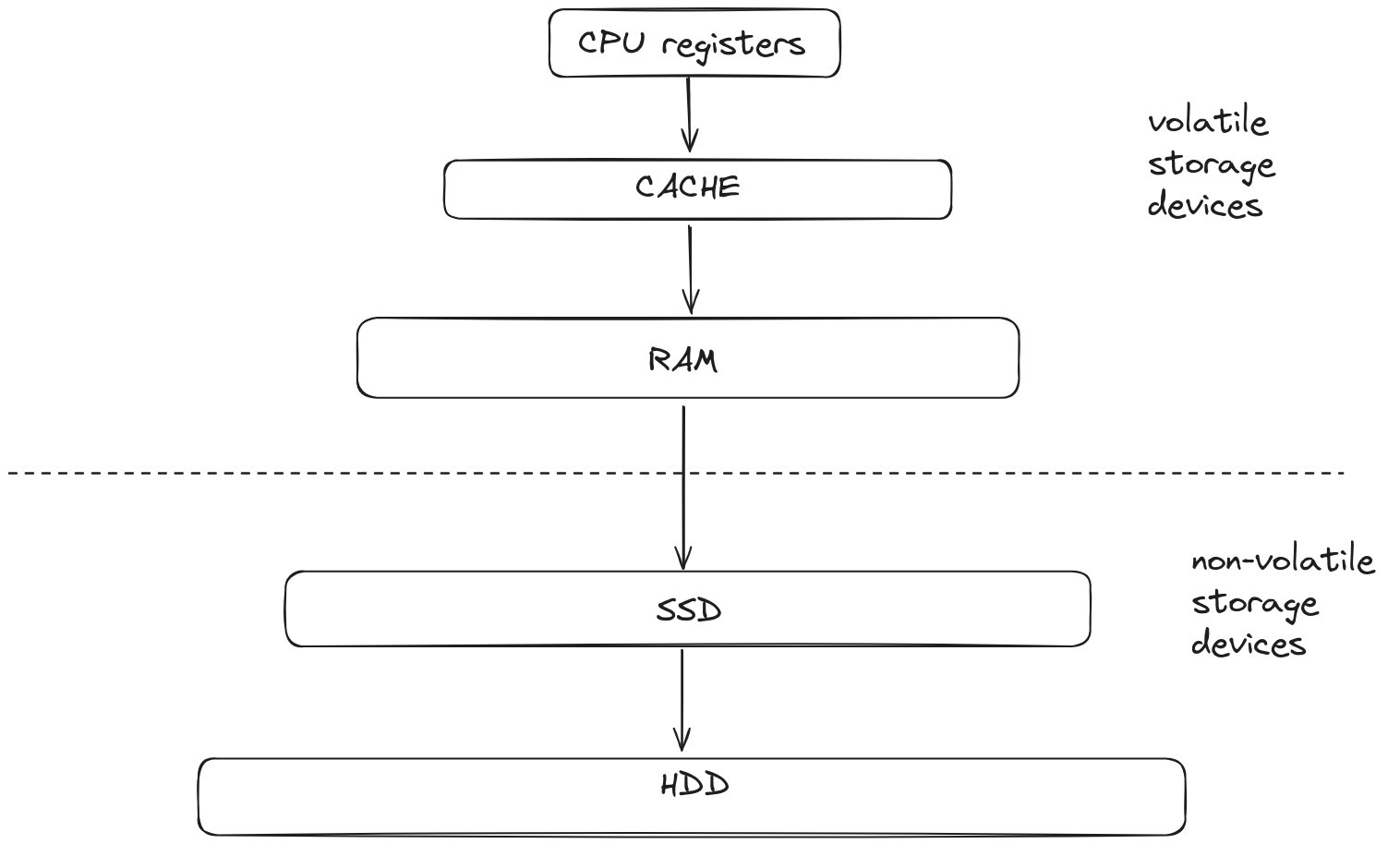
Storage devices are devices that are used to store data. There are mainly two types of storage devices: volatile and non-volatile.
Volatile Storage Devices
These devices are usually more expensive, faster, and have less storage capacity. Volatile storage devices require a constant supply of electricity to hold data. If the power is down, the data is completely lost.
Devices categorized as volatile storage devices include CPU Registers, CPU Cache, and RAM.
Non-Volatile Storage Devices
Non-volatile storage devices are usually less expensive and provide far more storage capacity than volatile storage devices but are very slow. These storage devices do not require a constant supply of electricity, meaning the data remains even when the power is off.
Devices categorized as non-volatile storage devices include SSDs, HDDs, DVDs, etc.
How does a DBMS store data on disks?
A DBMS stores databases in a single file or multiple files with hierarchical relationships, or it can use one file per relation, etc.
How are files structured?
Each file is divided into a bunch of fixed-sized chunks known as pages. The size of these pages varies from one DBMS to another. Storage is also divided into pages known as hardware pages, where the storage device can only guarantee an atomic write of a size equal to that of hardware pages. For instance, if the hardware page size is 4KB, then 4KB of data is written all at once or not written at all. There is no intermediate state.
How are pages structured?
There are several ways to structure a page, depending on whether the size of the records to be stored is fixed or variable. Records are stored in pages. For simplicity, the size of the record is generally limited to that of the page, and a record does not span multiple pages.
How are pages structured if the size of the records is fixed?
Records can be stored sequentially, one after another, just like an array. When the size of the records is not a multiple of the page size, the last part of the page is left unused to ensure that the record stays in one page instead of spanning multiple pages.
Insertion can be costly as one must parse the entire page to find an empty location. To handle this, the first empty record stores a pointer to the next empty record, and so on, forming a linked list of empty records known as a free list.
How are pages structured if the size of the records is variable?
The main problem with variable-sized records is that maintaining the free list is not helpful as the size of the record can change from one to another. If the size of an empty record found is 50 bytes and we want to insert a record of 56 bytes, which is not possible, to handle this slotted pages are used.
In variable-length records, the records have two parts. The first part has a fixed length and is the same for all the records of the same relation. The second part is the variable-length data.
The first part of the record consists of many pairs of values, where each pair stores the starting address and length of each attribute’s data. In pages, slots are used to track the records. A slot merely stores the starting and ending address of a record. These slots are present at the start of the page and grow towards the end of the page. Here, records are stored at the end and grow towards the start of the page. When both the slots and pages meet, we know that the page is full.
Log structure of pages
In this form, relations are stored as logs. For example:
INSERT A;
INSERT B;
INSERT C;
UPDATE A;
DELETE B;
Here, writing to the database is extremely fast, but reading is very slow because one must parse the entire log to get the desired record.
Generally, logs are added from start to end, and reading is done from end to start.
Reading from end to start can be helpful. Say we want to read record B. If we were reading from start to end, we would have to parse the entire file, but if we read from end to start, we can stop parsing as soon as we find the INSERT B; log.
How Are Tuples/Records Structured?
Tuples are simply a sequence of bytes that make sense to the DBMS. They generally contain:
Tuple header:
The tuple header stores metadata related to the tuple, such as the number of null attributes, the size of the tuple, the size of the attributes, etc.
Tuple Data:
The actual data for the attributes. These attributes are generally stored in the order specified in the table. For instance, if the table is defined as follows:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
....
);
Then tuples will be stored in the following order:

Unique Identifier: Each tuple in the database is assigned a unique identifier. The most common is a combination of page ID and an offset or slot.
What If the Size of a Tuple Is Greater Than the Size of a Page?
Sometimes, we need to store large files like images or videos. In cases where the size of a record exceeds the page size, the DBMS uses special pages known as overflow pages, and a pointer to the overflow page is stored in the record. If the data does not fit in a single record, it can span multiple overflow pages, or it can be stored in an entirely new file outside the database. A pointer to that data file is then stored in the record. However, some features offered by the DBMS may not apply to this external data file.
How are records organized in files?
So, how does the DBMS know which block to store the record in? There are multiple ways to organize records in files:
Heap File Organization:
- In heap file organization, records are stored in any available free space in the files, and there is no specific ordering of the records. Once stored, they are generally not moved.
- To find free space quickly, the DBMS uses an array of bytes where each byte corresponds to a page and stores a number representing the fraction of space that is free in that page. For example, if the page size is 8 bytes and the value stored is 6, then a 6/8th fraction of space is free in that page. This array of bytes is known as the free space map.
Sequential File Organization:
- In sequential file organization, records are stored in a specific order based on a search key. Sequential file organization is useful for displaying and computing queries.
- Each record stores a pointer to the next record, which comes after it sequentially. Here, the records are also stored as physically close as possible to reduce disk read time.
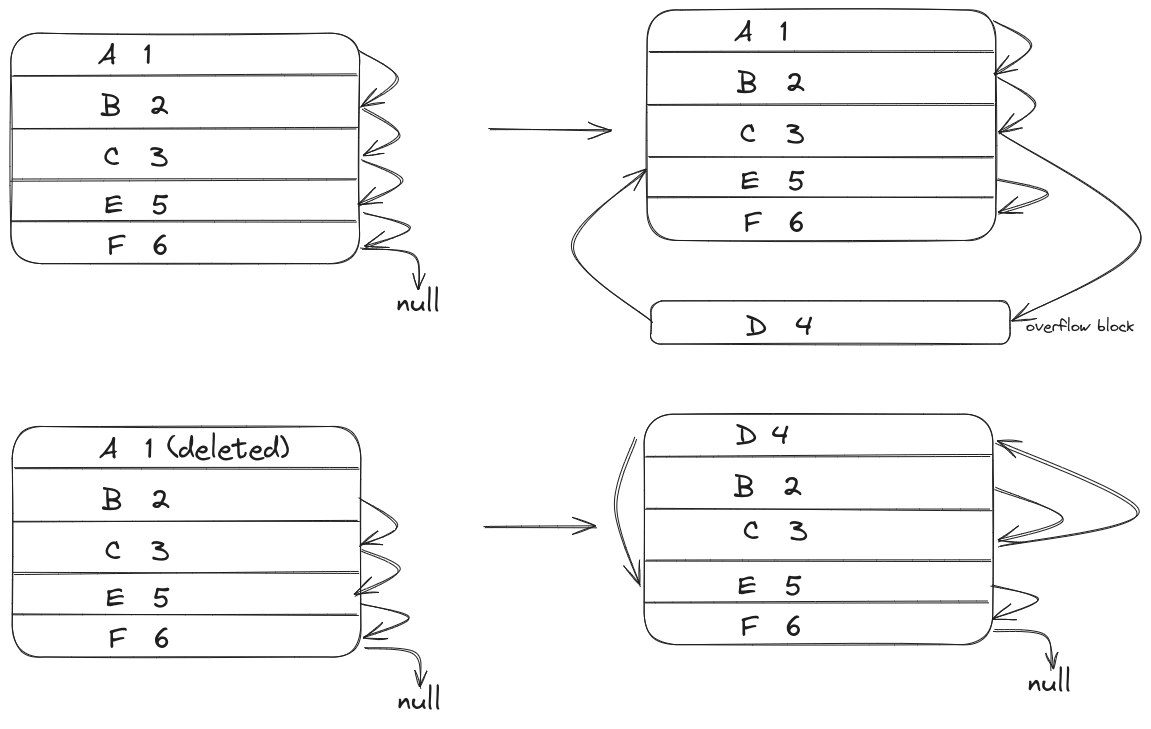
- For instance, say we have a relation stored in sequential file organization, and the search key is
Id. If we want to insert a new record, “D,” whoseIdis 4, the DBMS first locates the record that comes beforeId4, which is 3. if there is free space in the same block 4 is stored there; if not, 4 is stored as a new overflow block, and 3 points to that overflow block.
- Multitable Clustering File Organization:
- In multitable clustering file organization, records belonging to different relations are stored on a single page or block. This form of file organization helps when handling JOIN queries.
- However, reading records that belong to a single relation but are stored in multitable clustering can be slow, as the records will be spaced far apart.
- B+ Trees File Organization:
- B+ tree file organization uses a B-tree data structure to organize files. Here, the B+ tree provides very fast insert, read, delete, and update operations. The time complexity of B+ trees is
O(log(n))for both insertion and deletion. B+ trees are like evolved versions of binary trees.
- B+ tree file organization uses a B-tree data structure to organize files. Here, the B+ tree provides very fast insert, read, delete, and update operations. The time complexity of B+ trees is
- Hashing file organization
- In hashing file organization, a key is hashed to determine the location where the record should be stored. Hashing allows for both faster insertions and faster lookups, but the hash function used must be fast and distribute data uniformly. Hashing file organization is not suitable for OLAP-type workloads.
Why Does the DBMS Manage Memory Better Than the OS?
The DBMS can rely on the OS to load pages into memory when required. While this can be helpful, the DBMS can handle memory much better because it knows much more about the database files than the OS does. The DBMS can use its knowledge of database files to prefetch pages, search for pages more effectively, and so forth.
If the DBMS relies on the OS for managing memory, it can be dangerous because if any changes are made to a page, the OS can remove the page from memory without writing it back to disk, causing data loss since the DBMS has no control over the OS page cache.
Thus, many DBMSs have their own Buffer Pool that manages the loading of data to and from disk and memory. If an execution engine requests a specific page to execute a query, it makes a request to the Buffer Pool, which then loads the required page into memory and returns a pointer to it.
System Catalog
The DBMS needs to store information such as relations present in a database and files associated with the databases. The DBMS maintains a catalog that stores all the required data. Some additional data, such as the number of records, distinct records, and the sum of attributes, can also be stored using the DBMS’s own functionalities. However, metadata required for the catalog itself (a catalog of catalogs 😅) is also embedded in the software.
Workloads
Workloads refer to the general types of requests that the DBMS should process.
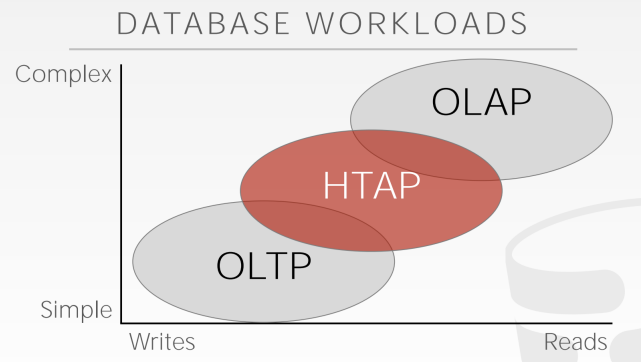
There are several different types of workloads, including Online Analytical Processing (OLAP), Online Transactional Processing (OLTP), Decision Support System (DSS), and Business Intelligence (BI).
The three main types of workloads are:
- OLTP(online transactional processing)
- Most of the query requests received by the database are short and mostly require accessing only one record. They usually involve insert, delete, and update operations. The time taken to process a request is minimal.
- OLAP(online analytical processing)
- Most of the query requests involve accessing most or all of the records in the table. These requests are usually analytical in nature and can be used to generate reports, analyze trends, etc. They usually take a long time to process, often hours.
- HTAP(Hybrid transaction + analytical processing)
- Most queries received by the DBMS are usually a mix of both OLAP and OLTP queries.
Storing Records Based on DBMS Workload
N-Ary Storage Model (NSM)
In this storage model, the records are stored normally, with a record containing the data of all attributes. This type of storage model is usually helpful for OLTP workloads, as the entire record can be modified in one place. However, it is not preferred for OLAP workloads because if a query requires only a few attributes of a relation, the entire page is loaded into memory, which contains attributes that are not needed. This wastes buffer pool memory and disk time (more time is taken to load).
Decomposition Storage Model (DSM)
In this storage model, only specific attributes are stored on a page. For example, if a relation has attributes A, B, and C, all values of attribute A are stored sequentially on one page, B on another, and so forth. So, when a query needs specific attributes of a relation, only those can be loaded into the buffer pool.
This storage model is suitable for OLAP workloads but not for OLTP, as all attributes of a record are stored on different pages. If we need to update a single record, we must update multiple pages.
The DBMS can use a fixed-length approach, where all attributes of the same record are stored at the same offset. So, if we want to access an attribute of a record, we can jump to that specific offset.
Another approach is the embedded tuple approach, where every tuple is embedded with a primary key of the corresponding tuple. This wastes memory by storing primary keys and is not widely used.